
In brief: Companies involved in the generative AI business keep making outrageous promises about unprecedented productivity improvements and cost cuts. Meta is now focusing on 3D model creation, which can seemingly be achieved with ease and very little input data thanks to a novel machine learning algorithm.
Researchers at Meta and Oxford University worked together on VFusion3D, a new method for developing scalable generative algorithms focused on 3D models. The technology was conceived as a way to overcome the main issue with foundation 3D generative models: the fact that there is not enough 3D data to train these new models on to begin with.

Images, text, or videos are abundant, the researchers explain, and they can be used to train "traditional" generative AI algorithms. However, when it comes to 3D models, specific assets are not as readily available. "This results in a significant disparity in scale compared to the vast quantities of other types of data," the study says.
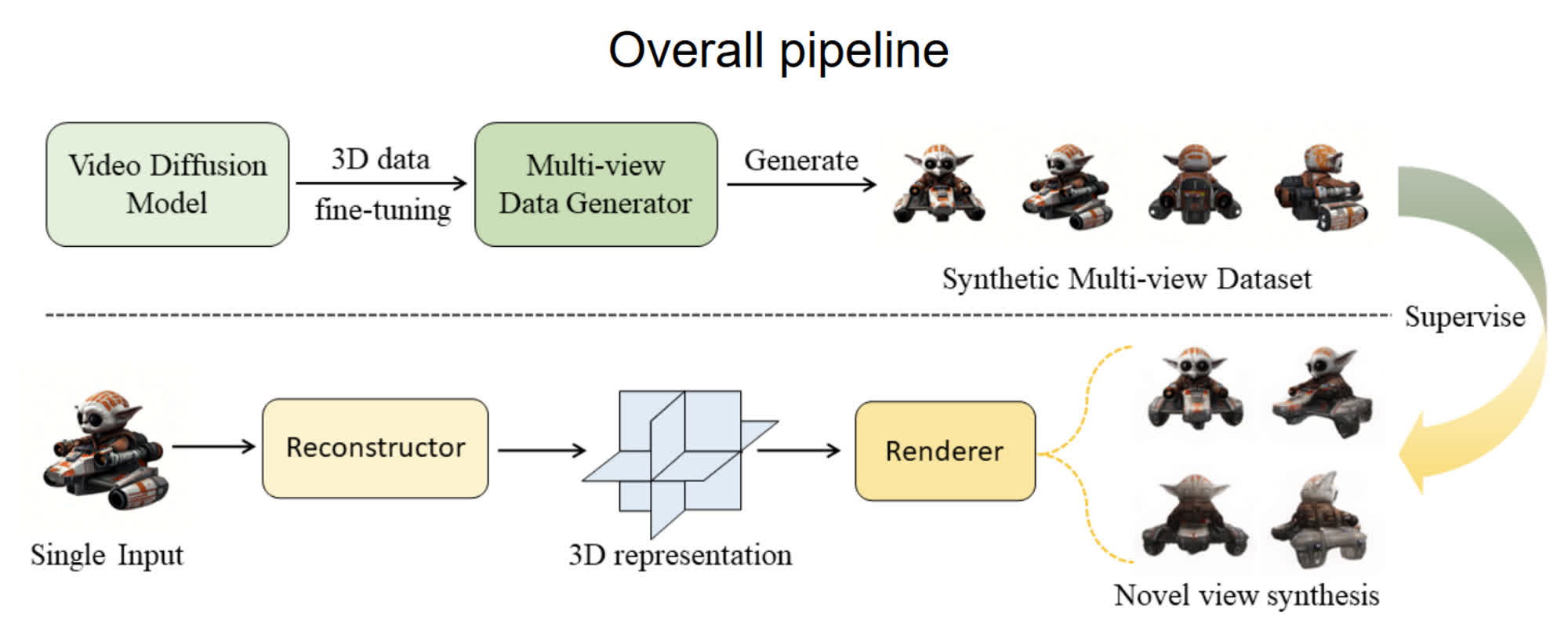
VFusion3D can overcome this problem by adopting a video diffusion model, which has been trained with extensive volumes of text, images, and even videos, as a source for 3D data. The new method can "unlock" its multi-view generative capabilities thanks to algorithmic fine-tuning, and it can also be used to generate a new large scale, synthetic dataset to feed new 3D generative models in the future.
The VFusion3D foundation model has been trained with nearly 3 million "synthetic multi-view data," the researchers say, and is now capable of generating a new 3D asset from a single (2D, we assume) image in mere seconds. VFusion3D can seemingly provide a higher performance level compared to other 3D generative models, and users are apparently preferring its results more than 90 percent of the time.
The official project page describes the pipeline adopted to develop VFusion3D. The researchers first used a finite amount of 3D data to tweak a video diffusion model, then turned said model into a multi-view video generator working as a "data engine." The engine was exploited to generate large amounts of weirdly synthetic assets, which were finally used to train VFusion3D as a proper generative AI algorithm.
VFusion3D can improve the quality of generated 3D assets when a larger dataset is used for training, the researchers say. By using "stronger" video diffusion models and more 3D assets, the algorithm can evolve even further. The final goal is to provide companies working in the entertainment business with a much easier way to create 3D graphics, although we hope there will be no underpaid, uncredited human workers hiding behind the generative AI uncanny curtains this time.